Updated: 2023-02-26
I’d been chatting with Kaliya Identity Woman for around a year, after contacting her about the potential for our collaborating on decentralized identity. At some point, she proposed the idea of writing a newsletter together, under the Identosphere.net domain.
Before embarking upon this project, we spent a lot of time figuring out how to run a newsletter: sustainably, affordably and with as few third party services as possible, while I learn the use of various web-tools.
We’re tackling a field that touches every domain, has a deep history, and is currently growing faster than anyone can keep up with. But this problem of fast-moving information streams isn’t unique to digital identity, and what we learn here could be of use in any conceivable domain.
GitHub Pages
I started in Decentralized ID creating freelance content, and ended up building an Awesome List, to organize my findings. Once that list outgrew the Awesome format, I began learning to create static web-sites with GitHub Pages and Jekyll.
I saved some useful guides along that path in my GitHub Pages Starter Pack
Static Websites are great for security and require minimal infrastructure, but if you’re trying to create any type of business online, you’re gonna want some forms so you can begin collecting e-mail subscribers! Forms are not supported natively through Jekyll or GitHub Pages.
Enter Staticman
Note: I’m not currently using these forms, because I didn’t have the energy to maintain, verses the use they were getting.
Staticman is a comments engine for static websites, but can be used for any kind of form, with the proper precautions.
It can be deployed to Heroku with a click of a button, made into a GitHub App, or run on your own server. Once set up, it will submit a pull-request to your repository with the form details (and an optional mailgun integration).
I set it up on my own server and created a bot account on GitHub with permissions to a private repository for the Staticman app to update with subscriptions e-mails to.
Made the form, and a staticman.yml config file in the root of the private repository where I’m collecting e-mail addresses.
The Subscription Form
<center>
<h3>Subscribe for Updates</h3>
<form class="staticman" method="POST" action="https://identosphere.net/staticman/v2/entry/infominer33/subscribe/master/subscribe">
<input name="options[redirect]" type="hidden" value="https://infominer.xyz/subscribed">
<input name="options[slug]" type="hidden" value="infohub">
<input name="fields[name]" type="text" placeholder="Name (optional)"><br>
<input name="fields[email]" type="email" placeholder="Email"><br>
<input name="fields[message]" type="text" placeholder="Areas of Interest (optional)"><br>
<input name="links" type="hidden" placeholder="links">
<button type="submit">Subscribe</button>
</form>
</center>
The staticman.yml config in the root of my private subscribe repo
subscribe:
allowedFields: ["name", "email", "message"]
allowedOrigins: ["infominer.xyz","identosphere.net"]
branch: "master"
commitMessage: "New subscriber: {fields.name}"
filename: "subscribe-{@timestamp}"
format: "yaml"
generatedFields:
date:
type: "date"
options:
format: "iso8601"
moderation: false
name: "infominer.xyz"
path: "{options.slug}"
requiredFields: ["email"]
It seems to be struggling with GitHub’s recent move to change the name of your default branch from master to main (for new repositories). So, unfortunately, I had to re-create a master branch to get it running.
Planet Pluto Feed Reader
In online media a planet is a feed aggregator application designed to collect posts from the weblogs of members of an internet community and display them on a single page. - Planet (Software)
One of the most promising projects I found, in pursuit of keeping up with all the info, is Planet Pluto Feed Reader, by Gerald Bauer.
For the uninitiated, I should mention that websites typically generate a machine readable copy of your blog in what’s called an RSS feed.
This allows anyone to follow your content in a newsreader, allowing users to keep up with posts from multiple locations without needing to visit each site individually.
Pluto Feed reader works just like a podcast app, but builds a simple webpage from the feeds added to it (or can be integrated with a Jekyll template).
Pluto is built with Ruby, using the ERB templating language for web-page design.
One of the cool things about ERB is it lets you use any ruby function in your web-page template, supporting any capability you might want to enable while rendering your news feed. This project has greatly helped me to learn the basics of Ruby while customizing its templates to suit my needs.
Feed Search
I use the RSSHub Radar browser extension to find feeds for sites while I’m browsing. However, this would be a lot of work when I want to get feeds for a number of sites at once.
I found a few simple python apps that find feeds for me. They aren’t perfect, but they do allow me to find feeds for multiple sites at the same time, all I have to do is format the query and hit enter.
As you can see below, these are not fully formed applications, just a few lines of code. To run them, it’s necessary to install Python, install the package with pip (pip install feedsearch-crawler), and type python at the command prompt, which takes you to a Python terminal that will recognize these commands.
From there you can type\paste python commands for demonstration, practice, or for simple scripts like this. I could also put the following scripts into their own feedsearch.py file and type python feedsearch.py, but I haven’t gotten around to doing anything like that.
Depending on the site, and the features you’re interested in, either of these feed seekers has their merits.
Feedsearch Crawler
from feedsearch_crawler import search
import logging
logging.basicConfig(filename='example.log',level=logging.DEBUG)
import output_opml
list = ["http://bigfintechmedia.com/Blog/","http://blockchainespana.com/","http://blog.deanland.com/"]
for items in list:
feeds = search(items)
output_opml(feeds).decode()
logger = logging.getLogger("feedsearch_crawler")
Feed seeker
from feed_seeker import generate_feed_urls
list = ["http://bigfintechmedia.com/Blog/","http://blockchainespana.com/","http://blog.deanland.com/"]
for items in list:
for url in generate_feed_urls(items):
print(url)
GitHub Actions
Pluto Feed Reader is great, but I needed to find a way for it to run a regular schedule, so I wouldn’t have to run the command every time I wanted to check for new feeds. For this, I’ve used GitHub actions.
This is an incredible feature of GitHub that allows you to spin up a virtual machine, install an operating system, dependencies supporting your application, and whatever commands you’d like to run, on a schedule.
name: Build BlogCatcher
on:
schedule:
# This action runs 4x a day.
- cron: '0/60 */4 * * *'
push:
paths:
# It also runs whenever I add a new feed to Pluto's config file.
- 'planetid.ini'
jobs:
updatefeeds:
# Install Ubuntu
runs-on: ubuntu-latest
steps:
# Access my project repo to apply updates after pluto runs
- uses: actions/checkout@v2
- name: Set up Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: 2.6
- name: Install dependencies
# Download and install SQLite (needed for Pluto), then delete downloaded installer
run: |
wget http://security.ubuntu.com/ubuntu/pool/main/s/sqlite3/libsqlite3-dev_3.22.0-1ubuntu0.4_amd64.deb
sudo dpkg -i libsqlite3-dev_3.22.0-1ubuntu0.4_amd64.deb
rm libsqlite3-dev_3.22.0-1ubuntu0.4_amd64.deb
gem install pluto && gem install nokogiri && gem install sanitize
- name: build blogcatcher # This is the command I use to build my pluto project
run: pluto b planetid.ini -t planetid -o docs
- name: Deploy Files # This one adds the updates to my project
run: |
git remote add gh-token "https://github.com/identosphere/identity-blogcatcher.git"
git config user.name "github-actions[bot]"
git config user.email "41898282+github-actions[bot]@users.noreply.github.com"
git add .
git commit -a -m "update blogcatcher"
git pull
git push gh-token master
Identosphere Blogcatcher
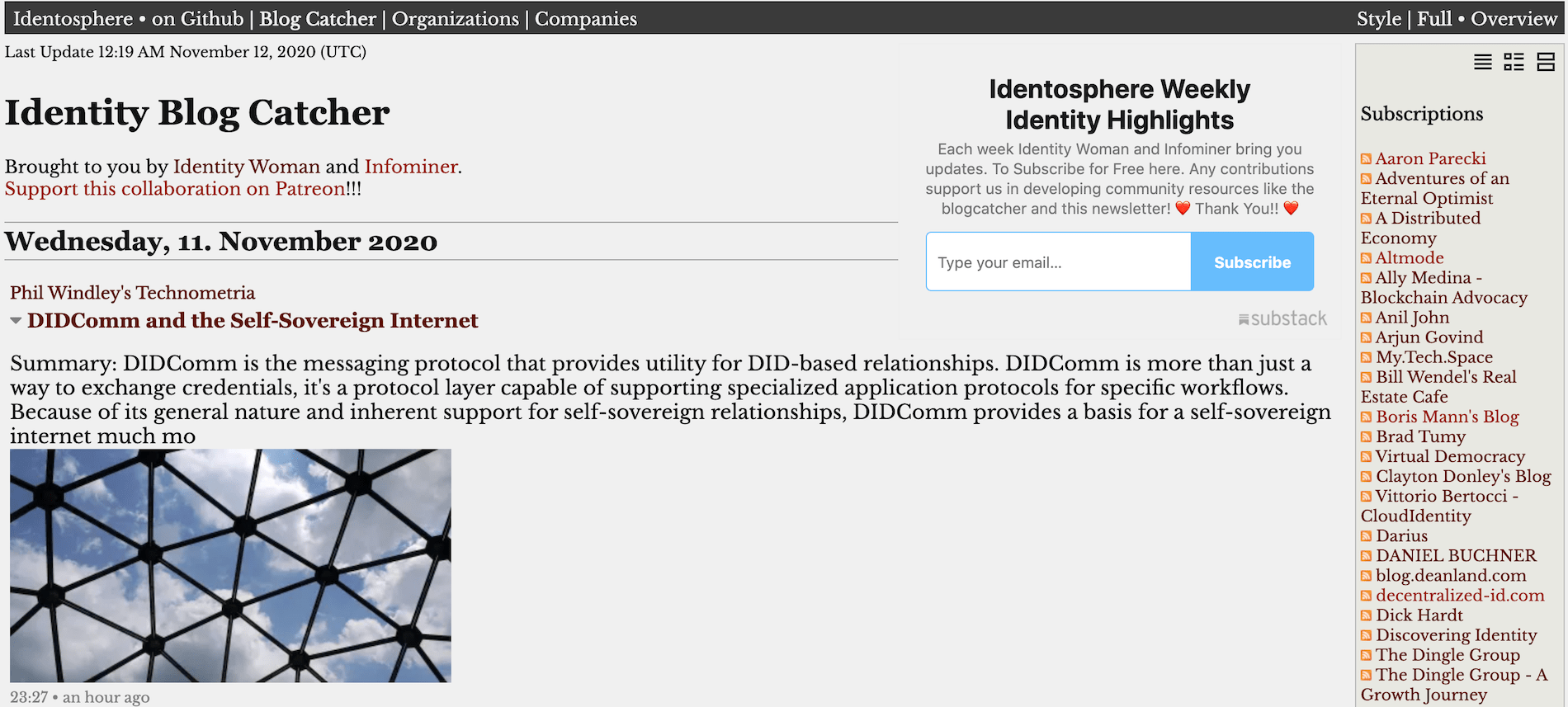
Identosphere Blogcatcher (source) is a feed aggregator for personal blogs of people who’ve been working on digital identity through the years, inspired by the original Planet Identity.
We also have a page for companies, and another for organizations working in the field.
Identosphere Weekly Highlights
After we got these pages up and running, we were ready to start our newsletter. This is just a small piece of the information portal we’re working towards, and not enough to make this project as painless and comprehensive as possible, but we had enough to get started.
Every week, we get browse the [BlogCatcher]identosphere.net), and share essential content others in our field will appreciate.
We’ll be publishing our 6th edition, at the start of next week, and our numbers are doing well!
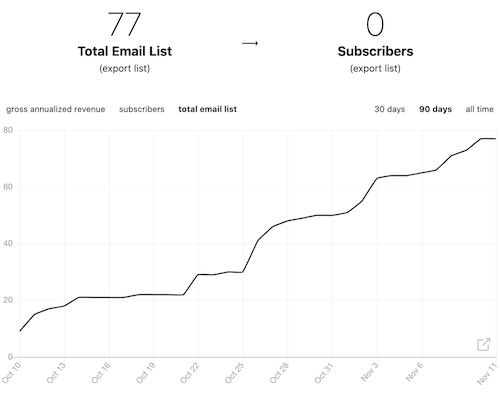
This newsletter is free, and a great opportunity for us to work together on something consistent while developing a few other ideas.
newsletter.identosphere.net
Setting up a newsletter without third-party intermediaries is more of a challenge than I’m currently up for, so we’ve settled on Substack for now, which seems to be a trending platform for tech newsletters.
It has a variety of options for both paid and free content, and you can read our content before subscribing.
Support us on Patreon
While keeping the newsletter free, we are accepting contributions via Patreon. (yes another intermediary, but we can draw upon a large existing userbase, and it’s definitely easier than setting up a self-hosted alternative.)
So far, we have enough to cover a bit more than server costs, and this will ideally grow to support our efforts, and enable us to sustainably continue developing these open informational projects.
Python, Twitter Api, and GitHub Actions
Since we’re publishing this newsletter, and I’ve gotten a better handle on my inner state, I decided it was time to come back to twitter. However, I knew I couldn’t do it the old way, where I manually re-tweeted everything of interest, spending hours a day scrolling multiple accounts trying to stay abreast of important developments.
Instead, I dove into the twitter api. The benefits of using twitter programmatically can’t be understated. For my first project, I decided to try an auto-poster, which could enable me to keep an active twitter account, without having to regularly pay attention to twitter.
I found a simple guide How To Write a Twitter Bot with Python and tweepy composed of a dozen lines of python. That simple script posts a tweet to your account, but I wanted to post from a pre-made list, and so figured out how to read from a yaml file, and then used GitHub actions to run the script on a regular schedule.
While that didn’t result in anything I’m ready to share here, quite yet, somewhere during that process I realized that I could write python. After playing around with Ruby, in ERB, to build the BlogCatcher, and running various python scripts that other people wrote, tinkering where necessary, eventually I had pieced together enough knowledge I could actually write my own code!
Decentralized ID Weekly Twitter Collections
With that experience as a foundation I knew I was ready to come back to Twitter, begin trying to make more efficient use of its wealth of knowledge, and see about keeping up my accounts without losing too much hair.
I made a script that searches twitter for a variety of keywords related to decentralized identity, and write the tweet text and some other attributes to a csv file. From there, I can sort through those tweets, and save only the most relevant, and publish a few hundred tweets about decentralized identity to a weekly twitter collection, that make our job a lot easier than going to 100’s of websites to find out what’s happening. :D
Soon, these will be regularly published to decentralized-id.com, which I found out is an approved method of re-publishing tweets, unlike the ad hoc method I was using before, sharing them to discord channels (which grabs metadata and displays the preview image \ text), exporting their contents and re-publishing that.
I do intend to share my source for all that after I’ve gotten the kinks worked out, and set it running on an action.
Twitter collections I’ve made so far
Decentralized-ID.com
Now we have a newsletter, and are seeking patrons, it seemed appropriate to work on developing decentralized-id.com, cleaning up some of its hastily thrown together parts, and adding a bunch of content to better represent the decentralized identity space.
That said, I’ve not given up on Bitcoin, or Crypto. On the contrary, I’m sure this work is only expanding my future capacity to continue working to fulfil the original vision of those resources.
Web-Work.Tools
With the information and skills i’ve gathered over the past year, web-work.tools was starting to look pretty out of date, relative to the growth of my understanding.
I updated GitHub Pages Starter Pack \ Extended Resources quite a lot to reflect those learnings, and separate the wheat from the chaff of the links I gathered when I was first figuring out how to use GitHub pages.